问题的提出?
企业数据库的数据量很大时候,即使服务器在没有任何压力的情况下,某些复杂的查询操作都会非常缓慢,影响最终用户的体验;当数据量很大的时候,对数据库的装载与导出,备份与恢复,结构的调整,索引的调整等都会让数据库停止服务或者高负荷运转很长时间,影响数据库的可用性和易管理性。如大型网站、省级人口系统、大型考试系统、大型物流系统、游戏平台等等,涉及海量数据的系统。微软提供了分区表、分布式分区视图、库表散列等,这些技术能很好的解决这类问题吗?
SQL Server数据库的一些数据分区技术
分区表技术
SQL Server 2005引入的分区表技术,让用户能够把数据分散存放到不同的物理磁盘中,提高这些磁盘的并行处理能力,达到优化查询性能的目的。但是分区表只能把数据分散到同一机器的不同磁盘中,也就是还是依赖于一个机器的硬件资源,不能从根本上解决问题。
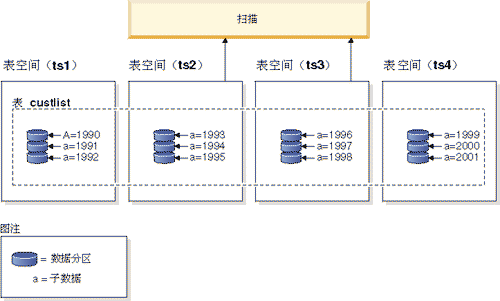
分区表
分布式分区视图
分布式分区视图允许用户将大型表中的数据分散到不同机器的数据库上,用户不需要知道直接访问哪个基础表而是通过视图访问数据,在开发上有一定的透明性。但是并没有简化分区数据集的管理、设计。用户使用分区视图时,必须单独创建、管理每个基础表(在其中定义视图的表),而且必须单独为每个表管理数据完整性约束,管理工作变得非常复杂。而且还有一些限制,比如不能使用自增列,不能有大数据对象。对于全局查询并不是并行计算,有时还不如不分区的响应快。
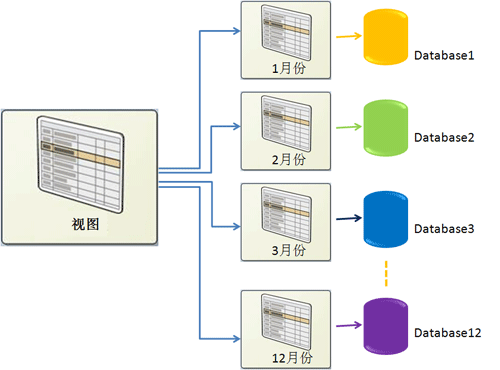
分布式分区视图
库表散列
一些大公司在开发基于库表散列的数据库架构,比如My Space经过数次数据库升级,最终采用按照用户进行的库表散列,微软为MSN/Hotmail和纳斯达克开发的数据依赖型路由(Data-Dependent Routing,DDR)。但是这些都是基于自己业务逻辑进行的,没有一个通用的实现。客户在实际应用中要投入很大的研发成本,面临很大的风险。
Moebius集群解决方案
面对海量数据库在高并发的应用环境下,仅仅靠提升服务器的硬件配置是不能从根本上解决问题的,Moebius分布式网格集群通过数据分区把数据拆分成更小的部分,分配到不同的服务器中。查询可以由多个服务器上的CPU、I/O来共同负载,通过各节点并行处理数据来提高性能;写入时,可以在多个分区数据库中并行写入,显著提升数据库的写入速度。
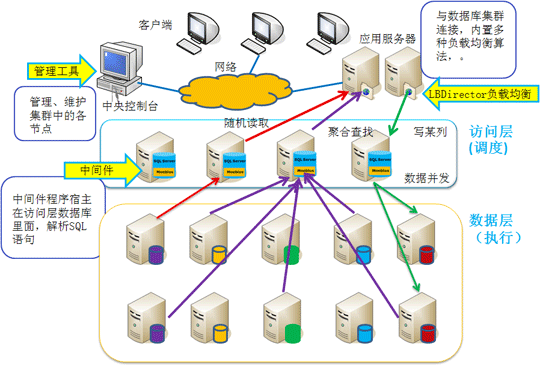
Moebius分布式网格集群
价值所在
- 通过分区把数据放到不同的机器中,每次查询可以由多个机器上的CPU,I/O来共同负载,通过各节点并行处理数据来提高性能。
- 冗余的数据结构(矩阵列)消除了单点故障,任何一个机器出现故障后都不会影响系统的正常
运行,数据库集群能提供不中断的服务。
- 无共享磁盘架构节省了硬件,利用中小型的服务器取代大型服务器大幅降低了硬件的成本,系统中不再有闲置的资源,降低了系统TCO(总体拥有成本)。
- 分区把数据分成更小的部分,提高了数据库的可用性和可管理性。
- 根据业务的需要,访问层和数据层都可以增加,Moebius集群具有良好的扩展性。
- 中间件宿主在数据库中的创新使集群变得更透明,数据库的管理成本,以及面向数据库的开发成本都最小化。